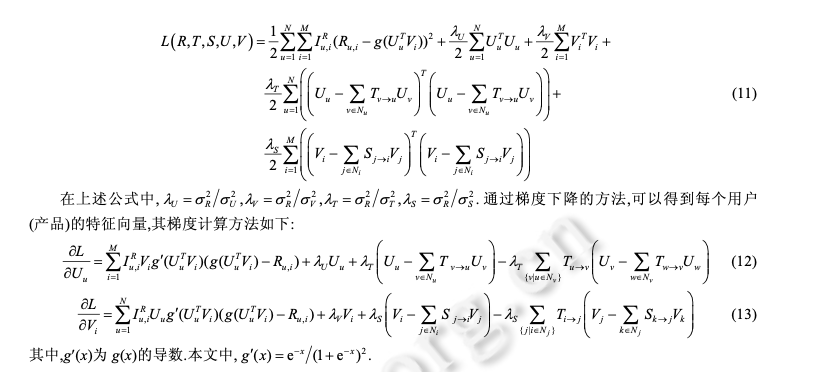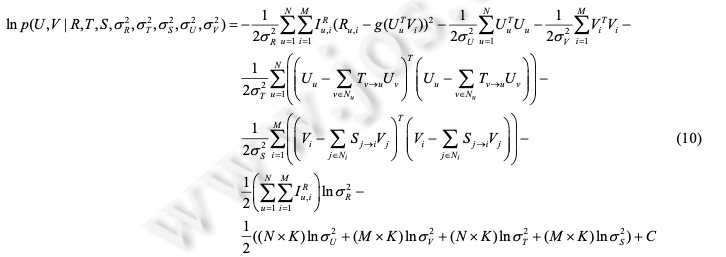基于时序行为的协同过滤推荐算法(Python) 课程论文+源码及数据
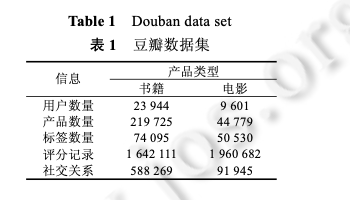
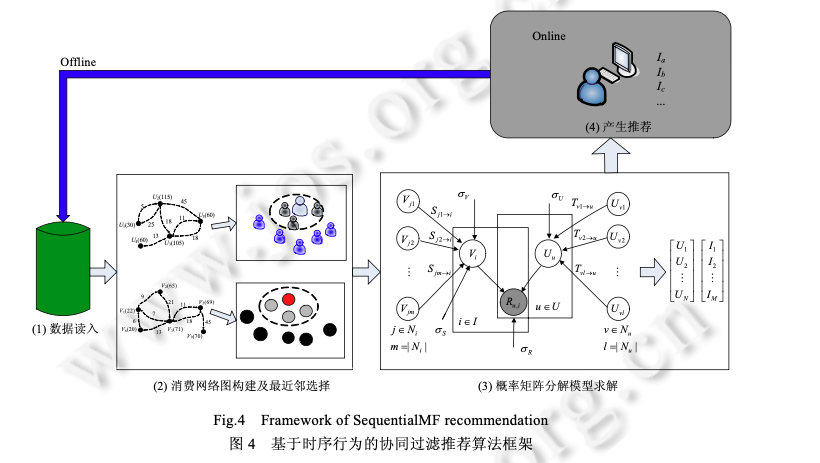
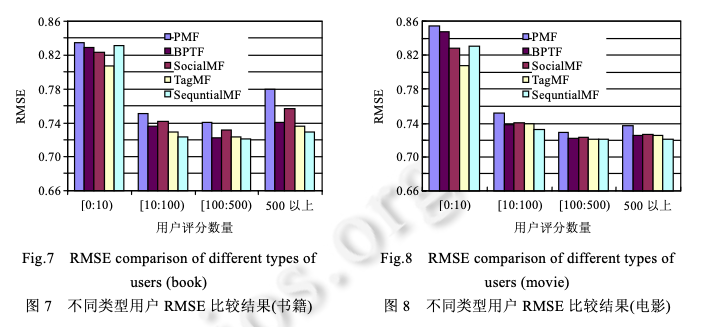
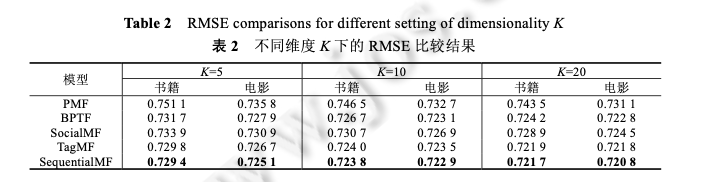
利用MovieLens数据,Pearson相似度,分别基于User和Item构建一个简单的kNN推荐系统,并给出RMSE评测1目录1相关工作 11.1 传统的协同过滤算法 11.2 基于时序信息的推荐算法 21.3 基于关系挖掘的协同过滤算法 22 问题定义和概率矩阵分解 33 SequentialMF 推荐算法描述 43.1 基于时序行为建模的最近邻选择 43.2 矩阵分解模型 53.3 SequentialMF时间复杂度分析 83.4 算法讨论 84 推荐框架 95 实验结果及分析 95.1 实验数据集 95.2 评价标准 105.3 比较算法及参数设定 105.4 实验结果与分析 126总结 151相关工作1.1 传统的协同过滤算法协同过滤(collaborative filtering,简称CF)利用与目标用户相似的用户行为(评分、点击次数等)推断目标用户对特定产品的喜好程度,然后根据这种喜好程度进行相应推荐 .目前,协同过滤推荐算法主要包括基于近邻 和基于模型两类.基于近邻的协同过滤算法首先是根据用户的历史信息计算用户(产品)之间的相似性,然后利用与目标用户 (产品)相似性较高的邻居对其他产品的评价来预测用户对特定产品的喜好程度,系统根据这一喜好程度对目标 用户进行推荐.目前,基于近邻的协同过滤算法主要包括基于用户的和基于产品的两类.基于用户的协同 过滤算法的核心在于找相似的用户,基于产品的算法主要是找相似的产品.与基于近邻的算法不同,基于模型的协同过滤算法主要通过用户对产品的评分信息训练出相应的模型,利用此模型预测未知的数据 .目前,基于模型的算法主要包括聚类模型 、概率相关模型 、潜在因子模型 、 贝叶斯层次模型等.最近,由于处理大数据的需要,Salakhutdinov 等人提出了利用低维近似矩阵分解模型进 行推荐的概率矩阵分解算法(probabilistic matrix factorization,简称 PMF),它一般假设每个用户的兴趣只受到少数几个因素的影响,然后将用户(产品)映射到低维的特征空间中,通过用户(产品)的评分信息来学习用户(产品) 的特征向量,从而重构评分矩阵,利用重构的低维矩阵预测用户对产品的评分,进行相应的推荐.由于用户和产 品的特征向量维数比较低,因而可以通过梯度下降的方法高效地求解.文献[17]中的实验结果表明,基于矩阵分 解的算法可以有效地处理大数据并能取得比较理想的精度.为了减少 PMF 当中参数设定对算法的影响, Salakhutdinov 等人进一步提出了贝叶斯概率矩阵分解算法(Bayesian probabilistic matrix factorization,简称 BPMF).BPMF 采用马尔可夫链蒙特卡洛算法进行参数估计,其推荐效果与 PMF 相比有了一定的提高.文献证明了 PMF 与概率主成分分析在理论上一致,在此基础上提出了 NPMF(non-linear PMF),NPMF 通过高斯过程 对 PMF 进行非线性扩展,进一步提高了算法效果.传统的协同过滤算法虽然能够进行相应的推荐,但其往往仅采用评分信息,而与之密切相关的时序信息和 关系信息则被忽略,有效利用这些信息可以进一步提高推荐算法的精度.许多学者以此为出发点,提出了基于时 序信息和关系信息的推荐算法.