 |
 |
| 首页 | 机械毕业设计 | 电子电气毕业设计 | 计算机毕业设计 | 土木工程毕业设计 | 视觉传达毕业设计 | 理工论文 | 文科论文 | 毕设资料 | 帮助中心 |
| 今天是: |
|>>> 您现在的位置:首页>>>>文档详细内容 |
| 设计 任务书 文档 开题 答辩 说明书 格式 模板 外文 翻译 范文 资料 作品 文献 课程 实习 指导 调研 下载 网络教育 计算机 网站 网页 小程序 商城 购物 订餐 电影 安卓 Android Html Html5 SSM SSH Python 爬虫 大数据 管理系统 图书 校园网 考试 选题 网络安全 推荐系统 机械 模具 夹具 自动化 数控 车床 汽车 故障 诊断 电机 建模 机械手 去壳机 千斤顶 变速器 减速器 图纸 电气 变电站 电子 Stm32 单片机 物联网 监控 密码锁 Plc 组态 控制 智能 Matlab 土木 建筑 结构 框架 教学楼 住宅楼 造价 施工 办公楼 给水 排水 桥梁 刚构桥 水利 重力坝 水库 采矿 环境 化工 固废 工厂 视觉传达 室内设计 产品设计 电子商务 物流 盈利 案例 分析 评估 报告 营销 报销 会计 | |||||
|
|||||
|
|||||
|
|||||
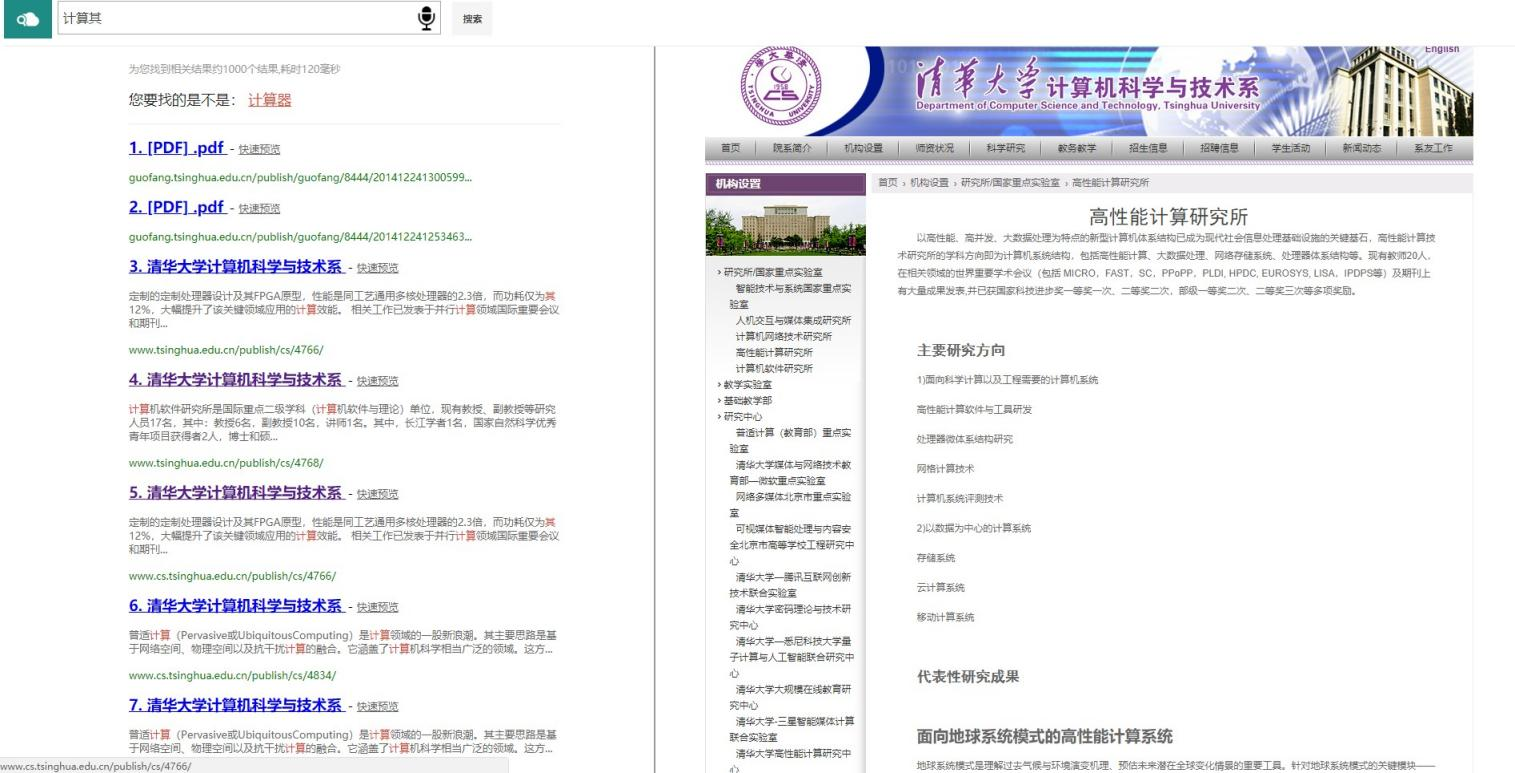
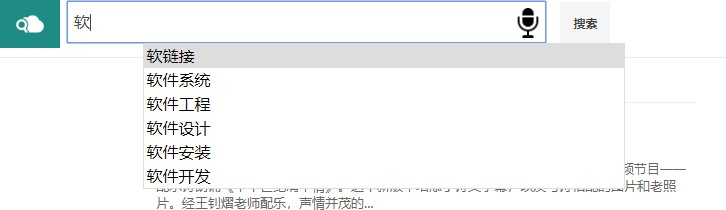
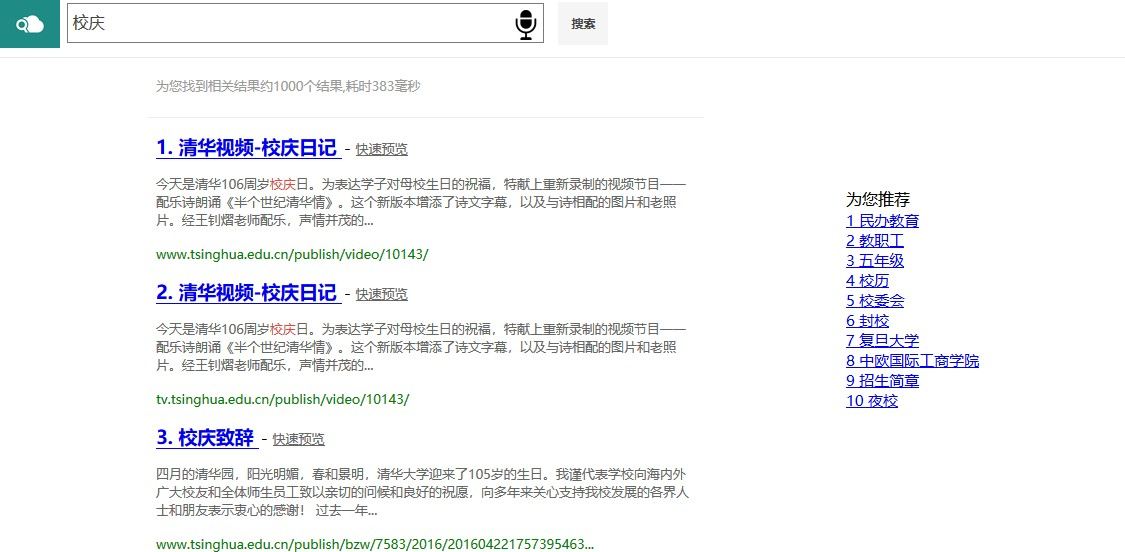
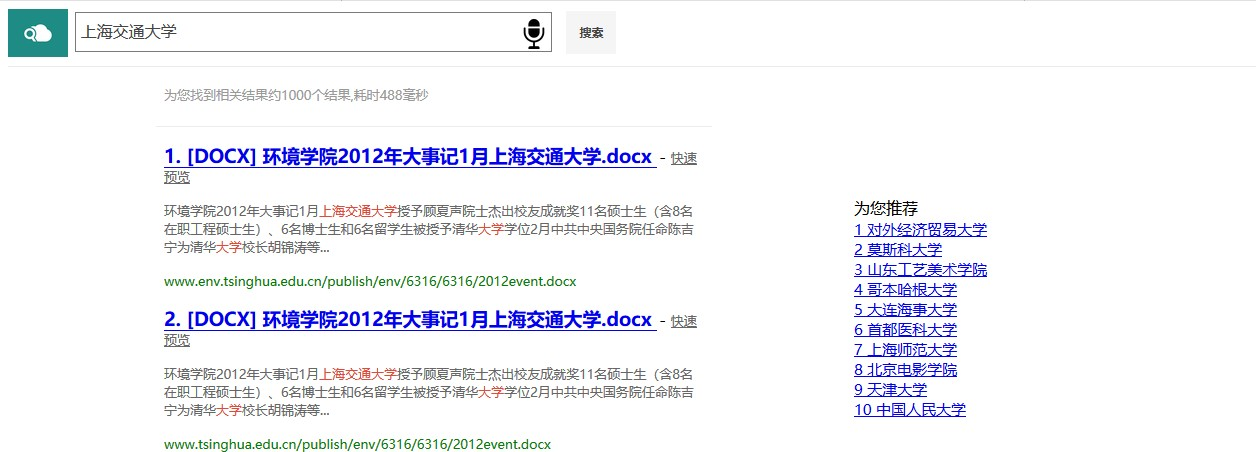
校园搜索引擎实验报告目录实验环境 1实验内容 1实现过程 2抓取校园网资源并处理 2分词处理 3词表建立 4结果排序 4查询提示 5查询纠错 5关键词高亮 5语音输入 5快速预览 5相关推荐 5使用说明 7主页 7查询推荐 7查询提示 8查询结果纠错 9页面预览 9性能评价 9概述 9查询样例 10构建相关性标注集合 10性能分析 11总结 11实验环境apache-tomcat-7.0.86 paoding-analysis-2.0.4-beta IDEA ULTIMATEwin10实验内容综合运用搜索引擎体系结构和核心算法方面的知识,基于开源资源搭建搜索引擎,具体包括如下几点:1.抓取清华校园网内绝大部分资源,并且进行预处理;2.基于Lucene实现校园搜索引擎――太强搜索;3.加入关键词纠错、查询提示、语音搜索、相关推荐功能,以提高太强搜索的体验;4.美化Web界面,实现关键词高亮、快速预览等功能;5.完成对于太强搜索的性能评价。实现过程抓取校园网资源并处理使用 Heritrix 抓取工具,抓取 HTML,PDF,M.S.Word 格式的文件28万份,共计31GB。编写 Python 脚本处理抓取到的数据,解析成 json 文件: 首先遍历所有抓取到的 文件,为每一个文件分配一个 ID,文件与 ID 一一对应,ID 用于之后PageRank的计算。获取文件的标题、文本 (docContent)、标签(h1~h6)、加粗(strong)信息等。使用BeatifulSoup 库解 析 HTML 文件内容,获取其中的超链接,为抓取到的整个数据包构建图结构, 根据图结构计算网页的 PageRank,使用pdfminer库解析pdf文件,使用docx2txt库解析word文件。我们发现实际抓到的html文件给出的charset有时是错误的,因此使用了chardet自动判断网页的编码,这样我们便可以处理几乎所有的编码。


毕业66资料站 biye66.com ©2015-2026 版权所有 | 微信:15573586651 QQ:3903700237
本站毕业设计和毕业论文资料均属原创者所有,仅供学习交流之用,请勿转载并做其他非法用途.如有侵犯您的版权有损您的利益,请联系我们会立即改正或删除有关内容!