汽车自动驾驶驶过交叉路口方法的对比研究 毕业论文+开题报告+过程检查记录表+Python源码及数据
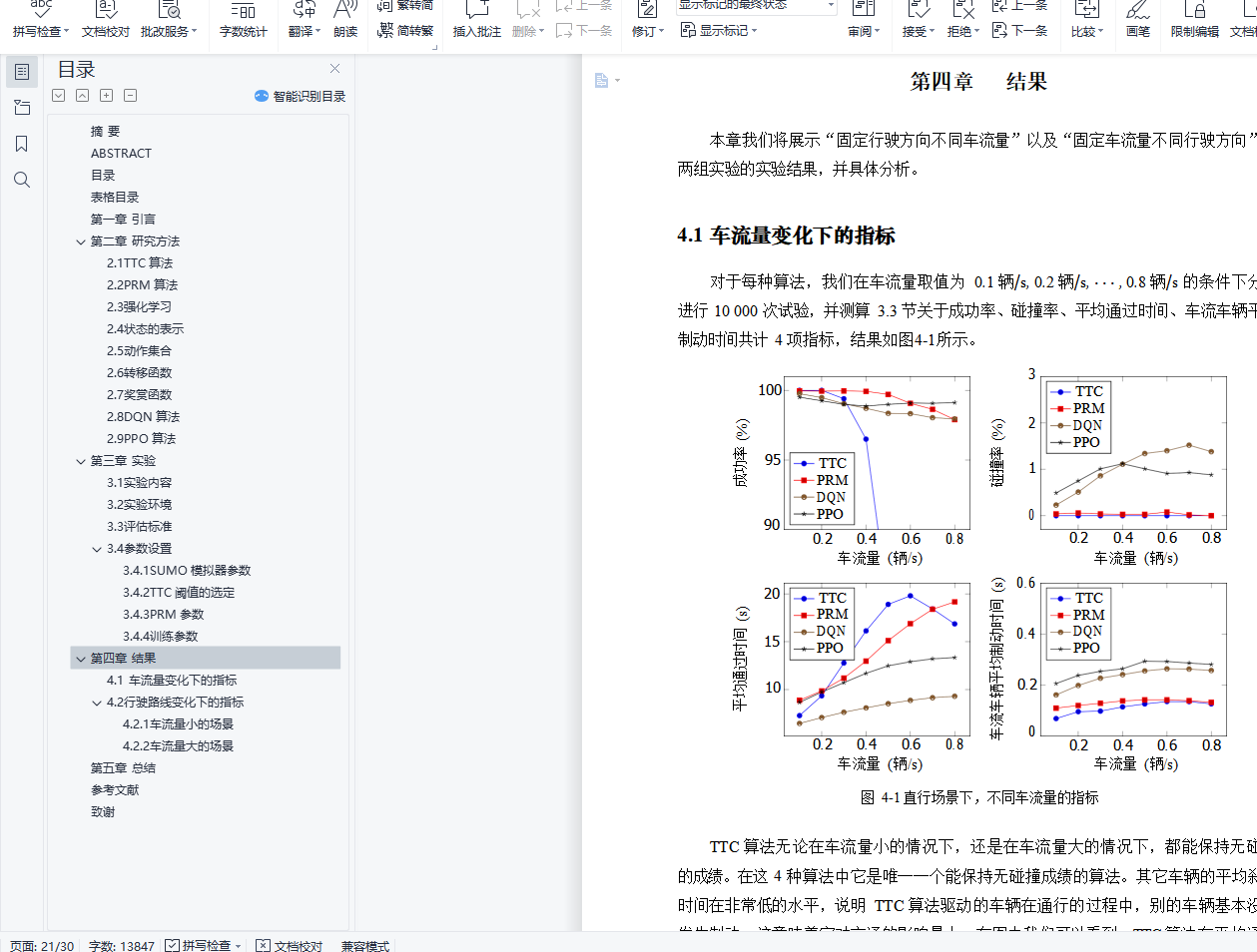
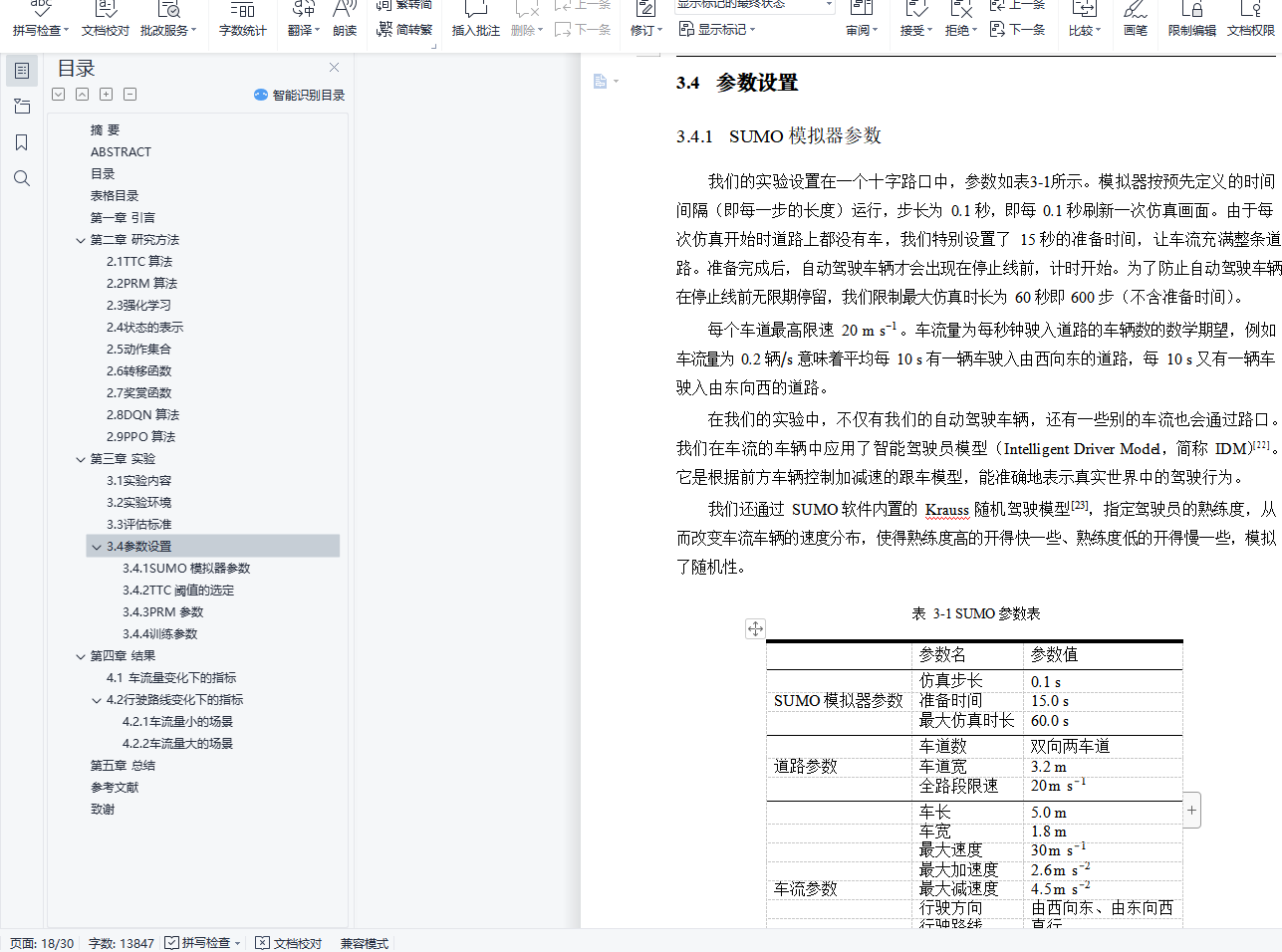
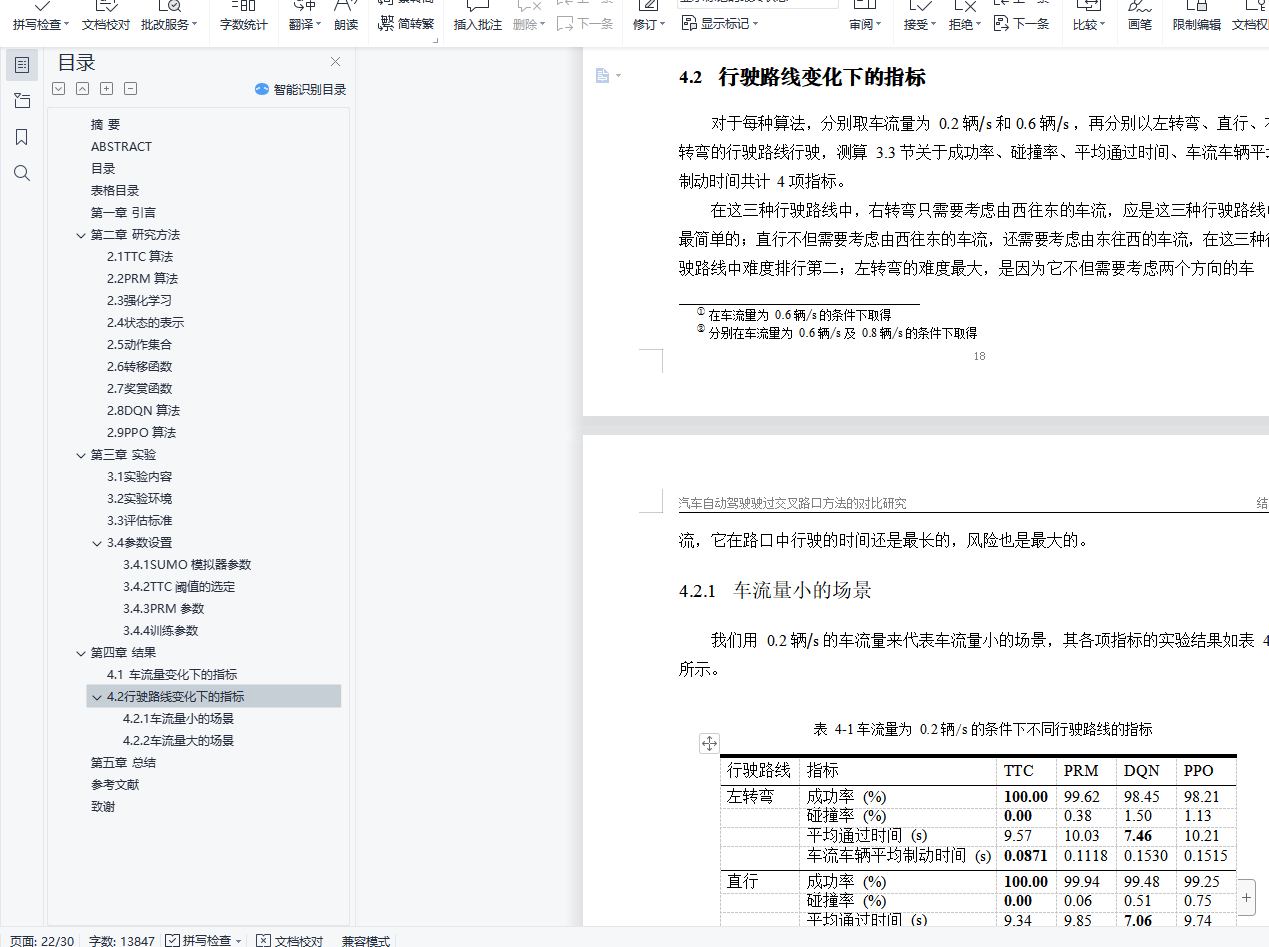
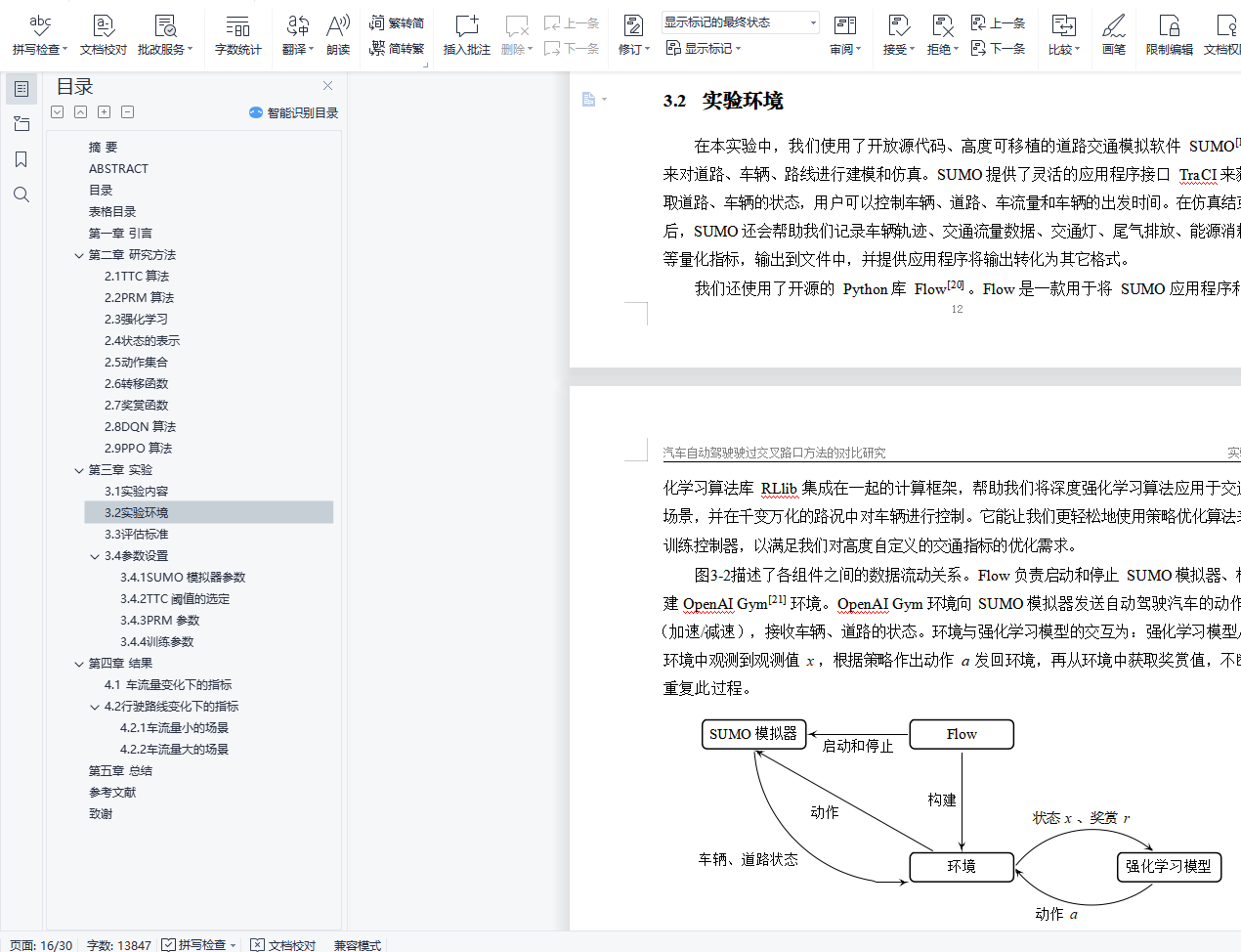
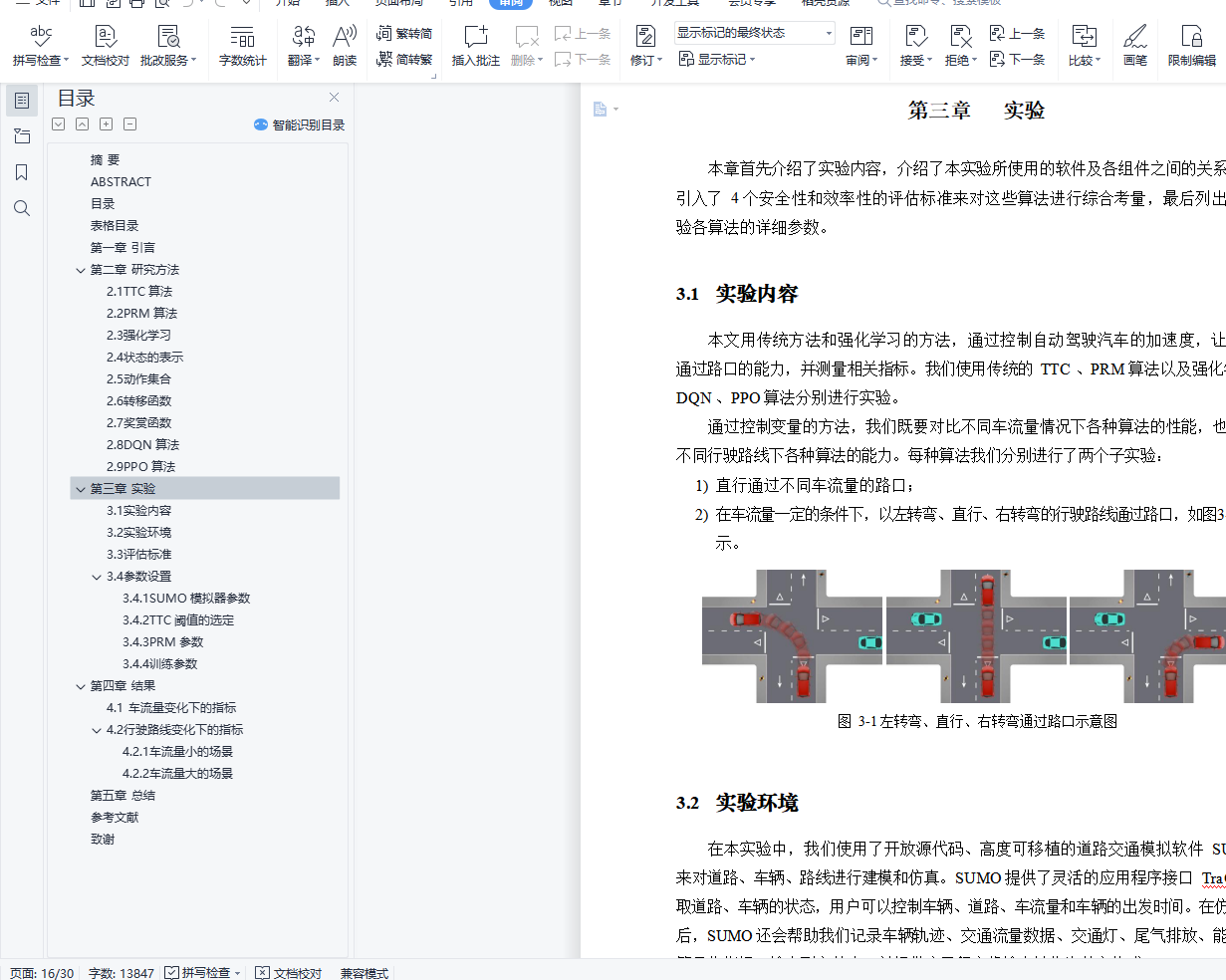
摘 要在自动驾驶领域,控制汽车通过路口是一件非常有挑战的事情,它需要兼顾安全和效率。我们的目标是让自动驾驶汽车不与其他汽车碰撞,同时让汽车通过路口的时间尽量短。在本文中,我们用传统方法和强化学习的方法来控制自动驾驶汽车通过无红绿灯路口,测算了它们的成功率、碰撞率、平均通过时间、车流车辆平均制动时间,并将它们做了比较。实验结果表明,传统方法的安全性远远超过强化学习方法,可保证不碰撞,但行驶方式过于保守;而强化学习方法能帮助我们在低碰撞率的条件下更快速地通过路口,大幅缩短了平均通行时间。我们目前实现的传统算法及强化学习方法虽然都并不够完美,但它们提供的解决方案为我们分别指出了这两种方法的优缺点,也为未来的研究指明了方向。关键词: 自动驾驶;强化学习;安全;导航Comparative Study of Controlling Autonomous Vehicles through Intersections ABSTRACTABSTRACTIn the field of autonomous driving, controlling vehicles through intersections is an ex- tremely challenging task. It needs to balance safety and efficiency. Our goal is to keep au- tonomous vehicles from colliding with other cars while letting vehicles pass through the inter- sections as fast as possible. This paper uses traditional methods and deep reinforcement learn- ing methods to control autonomous vehicles to pass through traffic-free intersections, measures their success rate, collision rate, average transit time, and average brake time. We compare the metrics above, and the experimental results show that the safety of the traditional method far exceeds the reinforcement learning method, which can prevent autonomous vehicles from col- liding with others, but its driving method is too conservative. The deep reinforcement learning method can help us dramatically reduce the average transit time with a low collision rate. Al- though the traditional method and the reinforcement learning method we currently implement are not perfect enough, the solutions provided by the methods above point out some advantages and disadvantages of the two methods, respectively, and also illustrate the direction for future research.Keywords: Autonomous Driving; Deep Reinforcement Learning; Safety; Navigation目录第一章 引言 1第二章 研究方法 22.1TTC 算法 22.2PRM 算法 32.3强化学习 42.4状态的表示 52.5动作集合 62.6转移函数 62.7奖赏函数 62.8DQN 算法 62.9PPO 算法 8第三章 实验 113.1实验内容 113.2实验环境 113.3评估标准 123.4参数设置 13第四章 结果 164.1车流量变化下的指标 164.2行驶路线变化下的指标 17第五章 总结 20参考文献 23致谢 25插图目录2-1TTC 计算方法示意图 32-2状态表示示意图 52-3用于标准化状态空间的神经网络 72-4将标准化状态空间映射为 Q 值的神经网络 82-5将标准化状态空间映射为 V 值的神经网络 82-6PPO 神经网络模型 103-1左转弯、直行、右转弯通过路口示意图 113-2各组件之间的数据流动关系 123-3不同 TTC 阈值下的指标 144-1 直行场景下,不同车流量的指标 16表格目录3-1SUMO 参数表 133-2PRM 参数表 153-3DQN 训练参数表 153-4PPO 训练参数表 154-1车流量为 0.2 辆/s 的条件下不同行驶路线的指标 184-2车流量为 0.6 辆/s 的条件下不同行驶路线的指标 19