 |
 |
| 首页 | 机械毕业设计 | 电子电气毕业设计 | 计算机毕业设计 | 土木工程毕业设计 | 视觉传达毕业设计 | 理工论文 | 文科论文 | 毕设资料 | 帮助中心 |
| 今天是: |
|>>> 您现在的位置:首页>>>>文档详细内容 |
| 设计 任务书 文档 开题 答辩 说明书 格式 模板 外文 翻译 范文 资料 作品 文献 课程 实习 指导 调研 下载 网络教育 计算机 网站 网页 小程序 商城 购物 订餐 电影 安卓 Android Html Html5 SSM SSH Python 爬虫 大数据 管理系统 图书 校园网 考试 选题 网络安全 推荐系统 机械 模具 夹具 自动化 数控 车床 汽车 故障 诊断 电机 建模 机械手 去壳机 千斤顶 变速器 减速器 图纸 电气 变电站 电子 Stm32 单片机 物联网 监控 密码锁 Plc 组态 控制 智能 Matlab 土木 建筑 结构 框架 教学楼 住宅楼 造价 施工 办公楼 给水 排水 桥梁 刚构桥 水利 重力坝 水库 采矿 环境 化工 固废 工厂 视觉传达 室内设计 产品设计 电子商务 物流 盈利 案例 分析 评估 报告 营销 报销 会计 | |||||
|
|||||
|
|||||
|
|||||
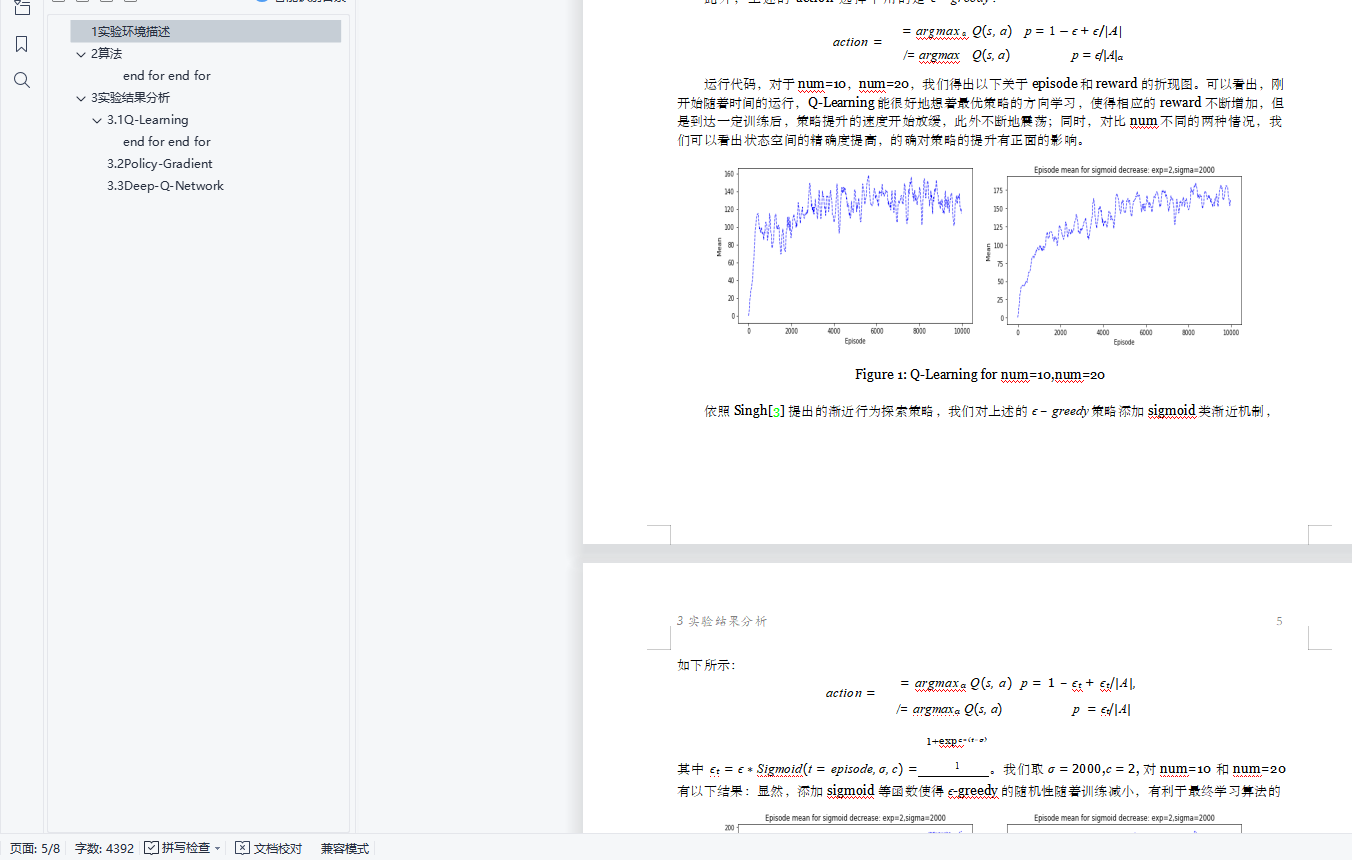
基于 CartPole-v0 环境的强化学习算法实现目录1 实验环境描述 12 算法 13 实验结果分析 33.1 Q-Learning 33.2 Policy-Gradient 53.3 Deep-Q-Network 61实验环境描述1.1CartPole-v0Cart Pole 在 OpenAI 的 gym 模拟器里面是相对比较简单的一个游戏。游戏里面有一个小车,上有一根杆子。小车需要左右移动来保持杆子竖直。如果杆子倾斜的角度大于 15°,那么游戏结束。小车也不能移动出一个范围(中间到两边各 4.8 个单位长度)。小车的状态变量有车的位置、杆子的角度、车速、角度变化率 4 个维度,以及左移、右移两个动作。左移或者右移小车的 action 之后,env 都会返回一个 +1 的 reward。到达 200 个 reward 之后,游戏也会结束。
毕业66资料站 biye66.com ©2015-2026 版权所有 | 微信:15573586651 QQ:3903700237
本站毕业设计和毕业论文资料均属原创者所有,仅供学习交流之用,请勿转载并做其他非法用途.如有侵犯您的版权有损您的利益,请联系我们会立即改正或删除有关内容!